Data Ingestion
Introduction
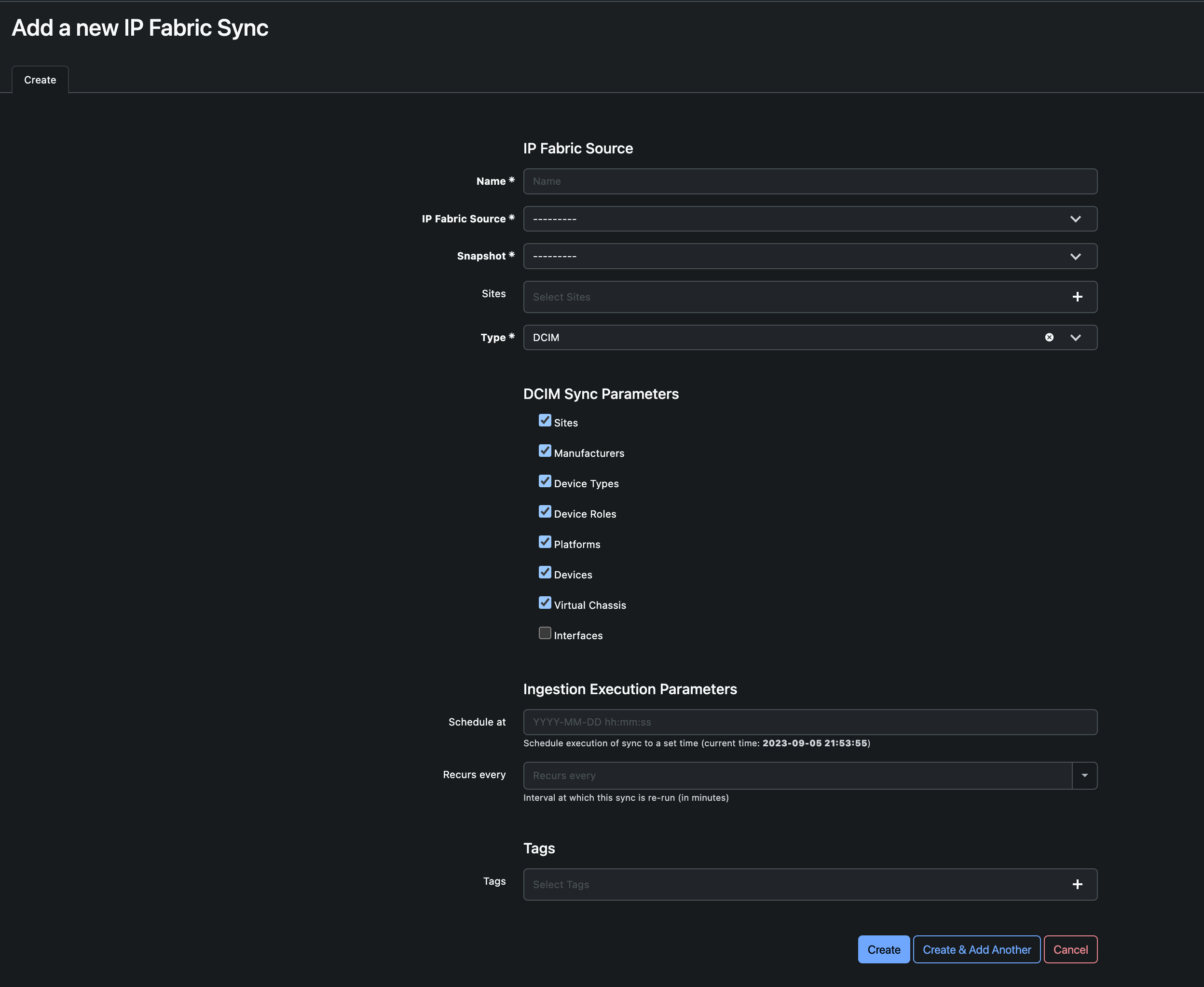
Data ingestion is a fundamental process in the plugin, enabling synchronization between IP Fabric and NetBox. This process involves configuring various parameters to define how data is synchronized. Let’s delve into the key components of data ingestion:
Configuration Parameters
A data ingestion configuration consists of several crucial parameters:
| Field | Description | Type |
|---|---|---|
| Name | The name of the ingestion job | CharField |
| Source | The IP Fabric instance used for data synchronization with NetBox | ForeignKey |
| Snapshot | The snapshot chosen for data synchronization with NetBox | ForeignKey |
| Auto Merge | Automatically merge staged changes into NetBox | BooleanField |
| Sites | Optional: Limits ingestion to specific sites | ChoiceField |
| Type | The type of ingestion (e.g., DCIM or IPAM) | ChoiceField (DCIM, IPAM) |
| Sync Parameters | Models to sync during ingestion | JSONField |
| Schedule At | Specify when to start the ingestion (if required in the future) | DateTimeField |
| Recurs Every | Determine the frequency of the ingestion | PositiveIntegerField |
| Tags | Apply tags to objects during ingestion | ForeignKey |
Note
When scheduling recurring ingestions using the Recurs Every field, it’s recommended to use the $last snapshot. This ensures that the ingestion always runs against the latest snapshot in IP Fabric, maintaining data consistency.
Data Ingestion Types and Synchronization Parameters
There are three distinct types of data ingestion configurations, each with specific synchronization parameters. These parameters act as toggles, allowing you to control whether models in NetBox should be created or updated, or if the ingestion should merely execute queries without making changes.
Even if a model is disabled, we continue processing the transformation map to utilize the data for querying an object. This is essential, because there may be a need to update or create another object based on the information. For example, even if device types are already present in NetBox, they must still be fetched during ingestion since they are mandatory for creating a device.
Here’s a breakdown of data ingestion types and their associated synchronization parameters:
- DCIM (Data Center Infrastructure Management)
- Site
- Manufacturer
- Device Type
- Device Role
- Platform
- Device
- Virtual Chassis
- Interface
- Mac Address
- IPAM (IP Address Management)
- VLAN
- VRF
- Prefix
- IP Address
- All
- Combines all the above
Data Ingestion Details
The data ingestion detail page offers insights into the ingestion configuration and its current status. Real-time status updates can be one of the following:
- New
- Queued
- Syncing
- Completed
- Failed
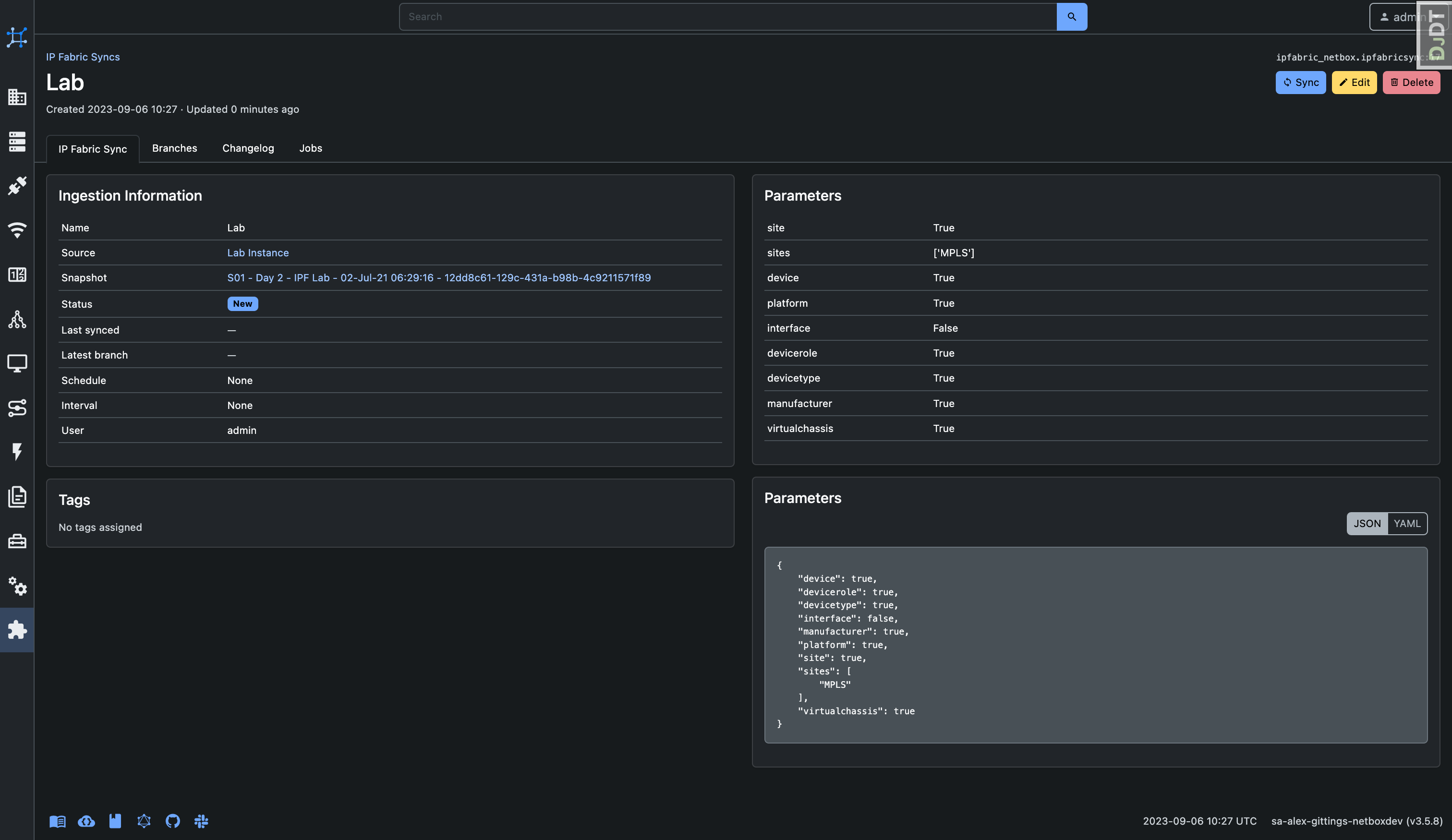
On the left, you can access snapshot information and the configured source for data ingestion. On the right, parameters for the data ingestion are displayed.
Tabs at the top provide access to various features, including viewing branches, accessing the change log, and reviewing associated jobs.
Initiating a Synchronization
Scenario 1: Fields Left Blank
During synchronization configuration, consider the Schedule At and Recurs Every fields. If left blank, the ingestion process won’t start immediately upon saving. Instead, you can manually trigger synchronization by clicking the Sync button on the Ingestion Detail page.
- Manual Initiation: Clicking
Syncwill instantly start the ingestion process. However, for this to happen, there must be an available runner capable of executing the job. If no runner is available, the job will be added to the default queue. This type of synchronization is known as an adhoc ingestion.
Scenario 2: Fields Populated
When you populate the Schedule At or Recurs Every fields during configuration, synchronization behavior changes:
- Scheduled Execution: The ingestion is scheduled to run at the specified time from the
Schedule Atfield. It repeats at regular intervals defined in theRecurs Everyfield.
- Immediate Execution (Fallback): If you omit a specific
Schedule Attime, the ingestion is scheduled to start immediately upon configuration. Subsequently, it continues at the intervals set in theRecurs Everyfield.
In summary, the plugin offers flexibility in initiating synchronization tasks. You can manually trigger them with the Sync button or set up automatic execution at designated times and intervals to meet your specific requirements. Once initiated, the latest branch can be seen in the branches tab.