Overview
The Technology tables enable the analysis and correlation of network state information and parameters on the fly. Most of the tables display live snapshot data generated by graph algorithms without a pre-existing cache. The first load of a large table usually takes longer than subsequent loads; however, all tables were built to handle large capacities and complex queries, so the outcome is likely to be better than analyzing the output in external applications like Excel.
Network or Site View
Tables display data for the whole network by default. To only display data for a specific site, select “site” from the drop-down menu on the top left.
Table Filtering
Simple or advanced filters can be applied to each table. By default, filtering is available above each column, and accepted filtering values can be strings, numbers, IP addresses, networks, Boolean values, or select box values.
RegEx Simple Column Filter Examples
=~(cis|ari)– RegEx matches alsociscooraristavalues (not exact match).=~^(cisco|arista)$– RegEx matchesciscooraristavalues only (exact match).=cisco– Matches onlyciscovalues (exact match).cis– Matchescisorcisco(prefix match).=~^(?!cisco)– RegEx negative lookahead – matches all except values starting withcisco.
Some columns containing IP addresses (such as Login IPv4 or Login IPv6 within Inventory →
Devices) can be filtered by entering the IP/prefix length in CIDR notation.
For example, 10.0.0.0/25 will find addresses between and including
10.0.0.128 and 10.0.0.255.
Additional Operators for Routing Columns
Columns containing IPv4 prefixes (such as Route within Technology →
Routing → Routes) have:
-
an additional operator “contains IP address” (API:
ip, UI:IP:)Example
IP:192.168.127.129will match any prefix containing that IP address, such as192.168.127.0/24or192.168.0.0/16, but not192.168.128.0/24.
- as well as a set of CIDR operators:
- is strict supernet (API:
gt, UI:>) - is supernet (API:
gte, UI:>=) - is strict subnet (API:
lt, UI:<) - is subnet (API:
lte, UI:<=) - overlaps (API:
sect, UI:@) - does not overlap (API:
nsect, UI:!@)
- is strict supernet (API:
Advanced Filters
Advanced filters can be used to construct arbitrarily complex expressions
by combining nested filters and filter groups with any number of logical
AND and OR operators between them. Advanced filters can be saved and
recalled for each specific table. Filters are stored per table and are
available to all users.
Device-based advanced filters
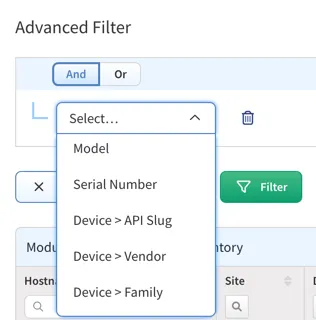
Supported device properties:
- Vendor
- Family
- Model
- Platform
- Version
- Image
- Type
- Login Ip
- Domain
- Uptime
- API Slug
- Attributes (via an attribute name)
These filters are available in most—though not all—tables. Certain tables, such as Site Summary tables, do not support device-based property filtering.
For detailed information, consult the Rapidoc documentation specific to your chosen table.
Accessing Rapidoc
To navigate to Rapidoc, follow these steps:
- Open the target table: Navigate to any table where you want to use Device-based advanced filters. Click the
...menu to access Table Description.
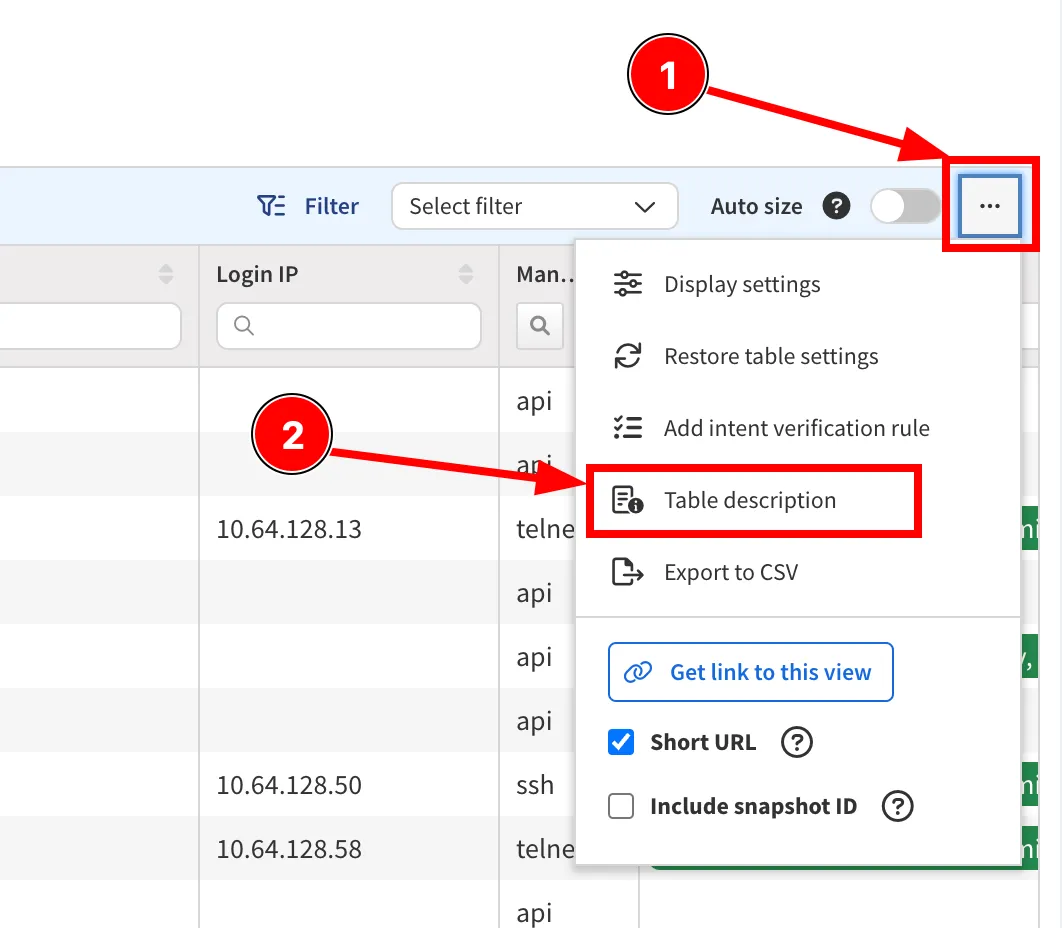
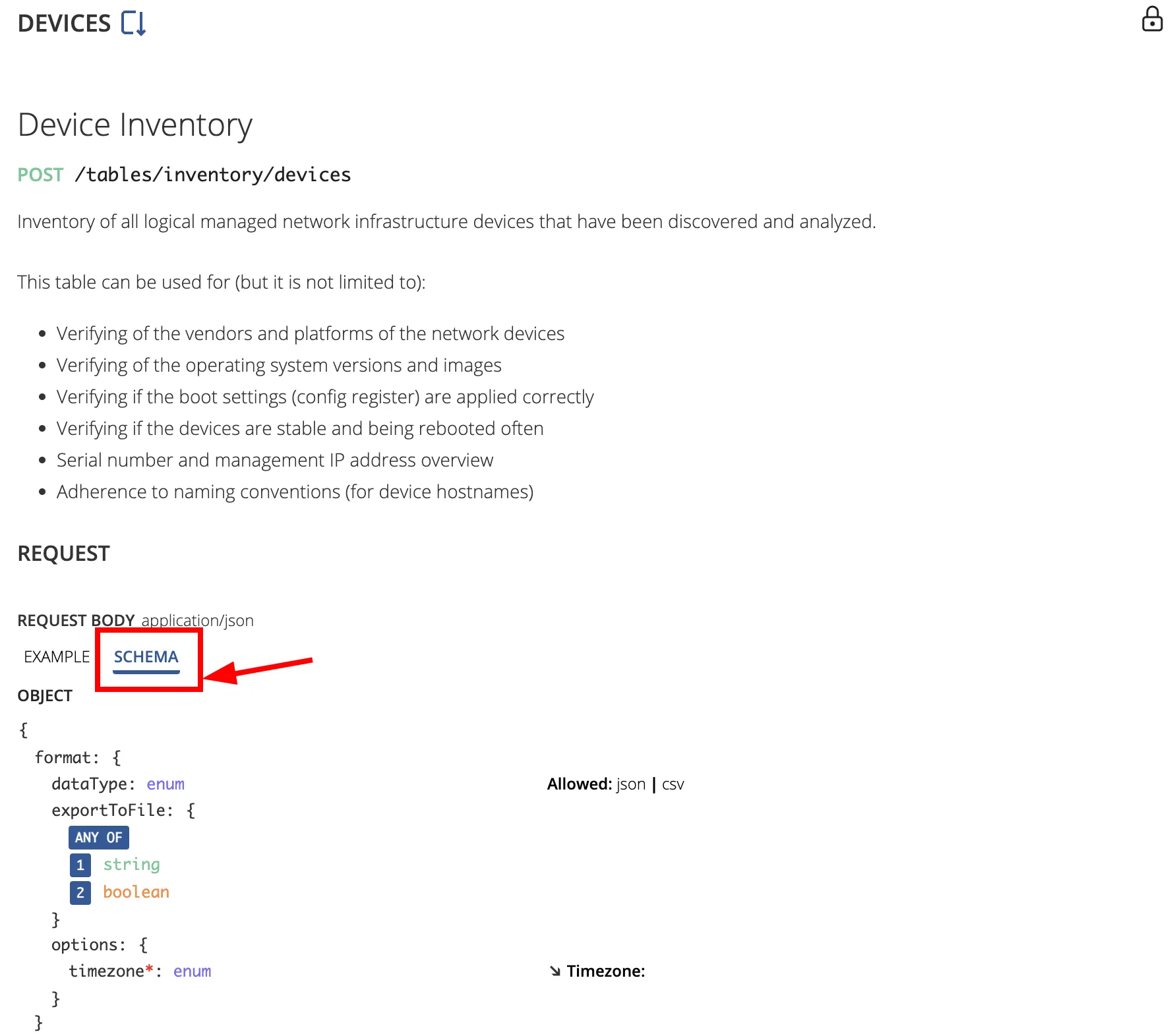
- Access API documentation: Scroll down and select API Documentation.

- Review applicable filters: Switch to the Schema tab to view all available filters for the selected table.
Note
For tables displaying a local device connected to a neighbor device, filtering is only supported for the local device.
Table Exports
Table outputs can be exported into CSV format for further processing, and
the text can be opened by any spreadsheet processor. In some cases,
Microsoft Excel and Google Spreadsheets convert strings from the CSV
files into dates, but these can remain as exact values by renaming the
content to string to force the spreadsheet to retain the original
content.
Note
It may take several seconds to prepare an export of large tables.
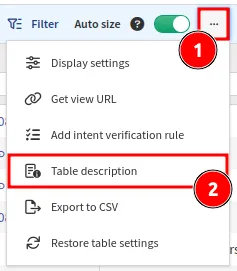
Tooltips
Each table contains built-in help in Table description under the ... menu
(in the top-right corner of the table):
Hover the mouse cursor over a column header for the column’s description:
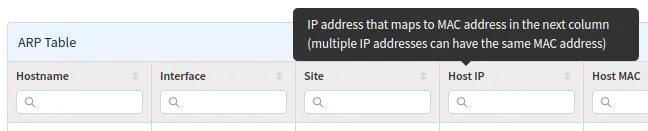
Column Visibility
Tables can be especially large to facilitate easier information correlation; however, not all columns need to always be visible.
Select Display settings under the ... menu and choose which columns to show
or hide:
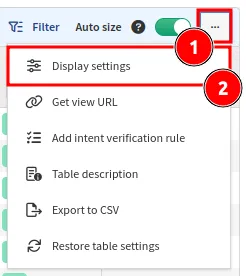
Column Size
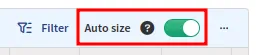
Use the Auto size toggle to either automatically size columns to fit their
current content (when enabled) or let columns remember user-defined widths
(when disabled):
Persistent Table View
To improve usability, each table remembers the settings and filtering for each user.
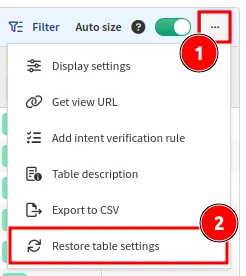
To reset a table to its original state, select Restore table settings under
the ... menu:
Regular Expression Syntax
Regular expressions are evaluated in the PostgreSQL using the POSIX standard with some extensions. Detailed information can be found in the Regular Expression Details section of the PostgreSQL documentation.
For a quick introduction to regular expressions, refer to Regular Expressions Quick Start guide on Regular-Expressions.info.
Literal Backlashes Require Different Amounts of Escaping Depending on the Context
\in bind variables (Table view mode) in the web UI (automatically escaped to\\unless the value is wrapped in double quotes and already escaped properly).\\in bind variables (JSON view mode) and queries in the web UI.
Create Links to Table Views
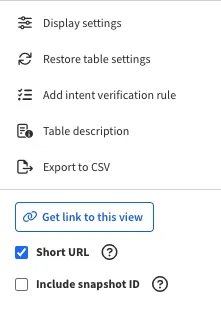
To point to a particular dataset, the link may include a snapshot ID that IP Fabric will switch to after opening.
Also, you can generate the link in two forms:
- A short form, like
https://<IPF_IP_or_FQDN>/inventory/devices?copyId=916264918z, is useful for sharing. - A long URL that contains the filter definition in JSON format:
https://<IPF_IP_or_FQDN>/inventory/devices?options=%7B"filters"%3A%7B"and"%3A%5B%7B"hostname"%3A%5B"like"%2C"L7"%5D%7D%2C%7B"or"%3A%5B%7B"vendor"%3A%5B"eq"%2C"cisco"%5D%7D%2C%7B"vendor"%3A%5B"eq"%2C"fortinet"%5D%7D%5D%7D%5D%7D%7D.- These URLs can be used, for example, to generate templates for your automations. You can prepare the structure of a filter using the Advanced Filter GUI, then replace values with variables in your automation scripts.
Pin Pages to the Main Menu for Quick Access
Pin a Page to the Main Menu
To pin any page in the Technology Tables, click the pin button next to the table name. The page will instantly appear in the left Main Menu.

Unpin a Page from the Main Menu
If you no longer want it in the Menu, you can unpin it by clicking the pin in the Main Menu or by clicking the pin next to the page title again.
